LLM-Aufrufe reduzieren mit Vector Similarity Search
Eines meiner absoluten Highlights bei der Codemotion Milano 2025 war der Vortrag von Raphael De Lio (Redis). Er bot die perfekte Mischung aus technischer Klarheit und praktischer Relevanz, und die Kernidee beschäftigt mich seitdem immer wieder.
Die Idee: Modelle klüger einsetzen, nicht größer
Statt jede Anfrage durch ein LLM zu schicken, zeigte Raphael, wie Semantic Routing, Vector Similarity Search (VSS) und Semantic Caching den Token-Verbrauch, die Latenz und den Energieverbrauch drastisch reduzieren können, ohne dabei Qualität oder Kontext einzubüßen.
Er demonstrierte drei konkrete Anwendungsfälle:
- Textklassifikation. Anstatt ein LLM jede Eingabe klassifizieren zu lassen, vergleicht man das Embedding der Anfrage per Vektorähnlichkeit mit bekannten Kategorien. Für viele Aufgaben ist das schneller, günstiger und genauso präzise.
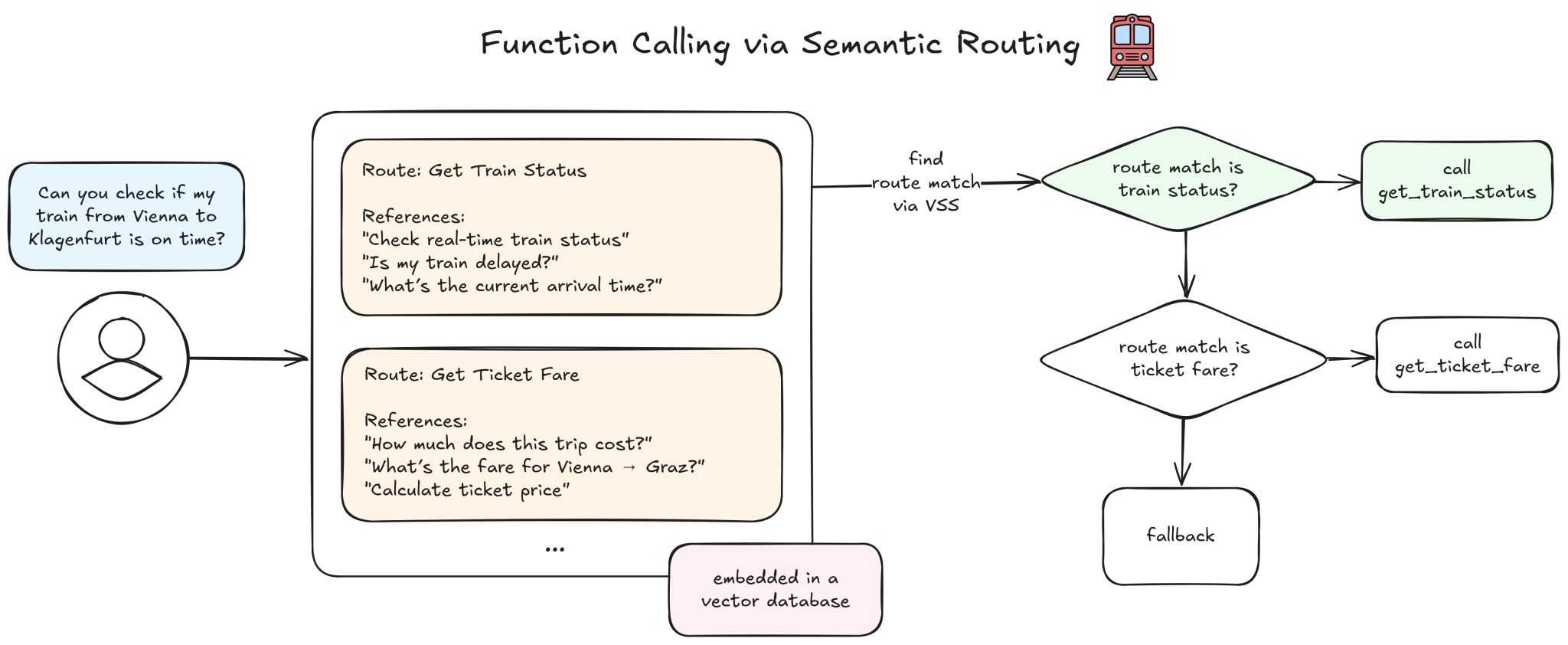
- Function Calling. Statt das Modell bei jeder Anfrage entscheiden zu lassen, welche Funktion aufgerufen werden soll, matcht man die Nutzerintention gegen vorberechnete Embeddings der Funktionsbeschreibungen. Das richtige Tool wird ohne LLM-Roundtrip ausgewählt.
- Caching von Antworten. Wenn eine semantisch ähnliche Frage bereits beantwortet wurde, wird das gecachte Ergebnis ausgespielt. Keine neue Generierung nötig, wenn eine gleichwertige Antwort bereits existiert.
Effizienz als Verantwortung
Was mich am meisten angesprochen hat, war der zugrundeliegende Denkansatz: Nicht durch den Einsatz größerer Modelle skalieren, sondern durch klügeren Einsatz. Jeder unnötige LLM-Aufruf kostet Tokens, erzeugt Latenz und verbraucht Energie. Effizienz ist hier nicht nur Optimierung, sondern Verantwortung.
Das deckt sich direkt mit dem, was ich in der Praxis sehe. Viele Produktivsysteme machen weit mehr LLM-Aufrufe als nötig, nicht weil das Modell gebraucht wird, sondern weil es der Standardpfad ist. Eine vorgeschaltete Similarity-basierte Routing-Schicht kann die Kosten erheblich senken und dabei die Antwortqualität beibehalten oder sogar verbessern.
Ressourcen
Ich empfehle Raphaels Material sehr:
Danke, Raphael, für einen Vortrag, der technische Tiefe mit einer Vision für nachhaltige KI-Infrastruktur verbindet!