Reduce LLM Calls with Vector Similarity Search
One of my absolute highlights at Codemotion Milano 2025 was the talk by Raphael De Lio (Redis). It was a perfect mix of technical clarity and practical impact, and the core idea has stuck with me ever since.
The Idea: Call Models Smarter, Not Bigger
Instead of sending every query through an LLM, Raphael showed how semantic routing, vector similarity search (VSS) and semantic caching can dramatically reduce token usage, latency and energy consumption, while keeping quality and context intact.
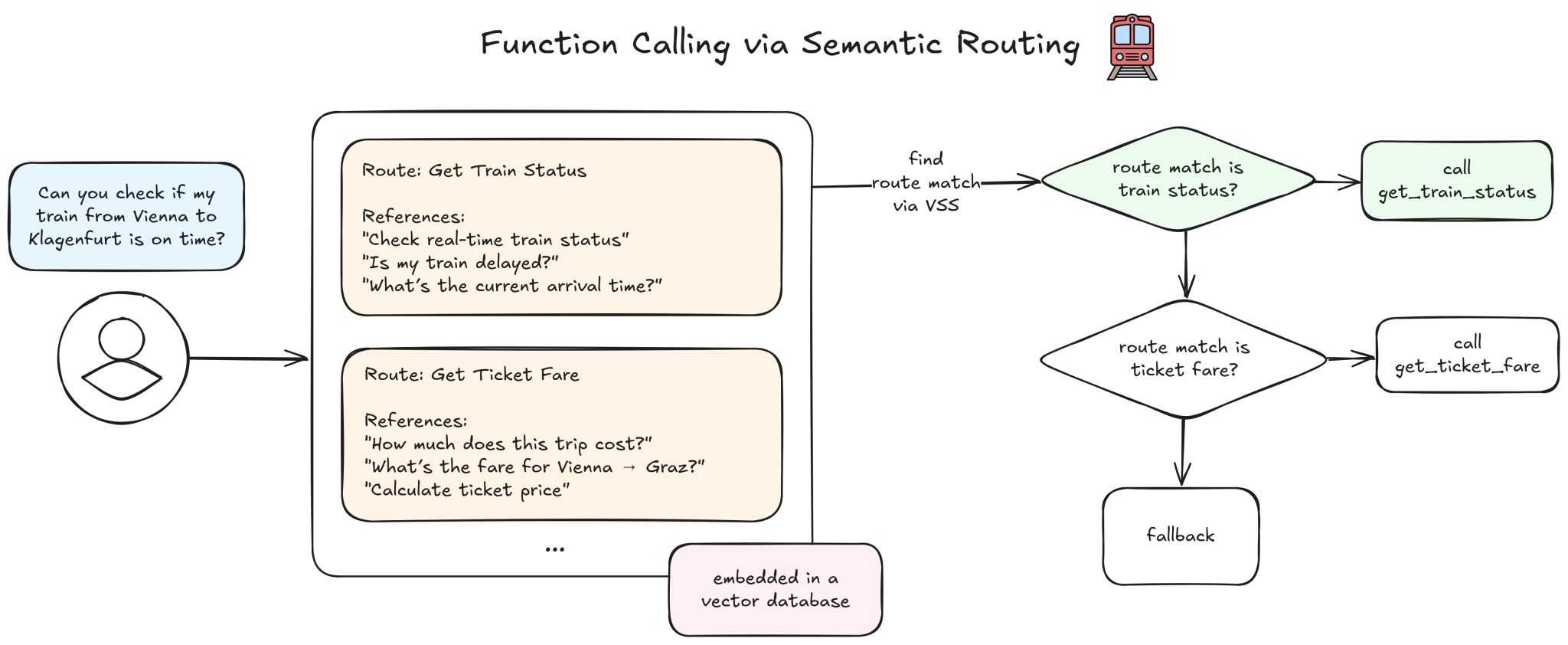
He demonstrated three concrete use cases:
- Text classification. Rather than prompting an LLM to classify every input, you compare the query’s embedding against a set of known categories using vector similarity. For many tasks, this is faster, cheaper and just as accurate.
- Function calling. Instead of letting the model decide which function to call on every request, you match the user’s intent against pre-embedded function descriptions. The right tool gets selected without an LLM round-trip.
- Caching responses. If a semantically similar question has already been answered, serve the cached result. No need to generate a new response when an equivalent one already exists.
Efficiency as Responsibility
What resonated with me most was the underlying mindset shift: don’t scale by calling bigger models, scale by calling them smarter. Every unnecessary LLM call costs tokens, adds latency and consumes energy. Efficiency here isn’t just optimisation, it’s responsibility.
This connects directly to what I see in practice. Many production systems make far more LLM calls than necessary, not because the model is needed, but because it’s the default path. Introducing a similarity-based routing layer before the model can cut costs significantly while maintaining (and sometimes even improving) response quality.
Resources
I highly recommend checking out Raphael’s material:
Thanks, Raphael, for a talk that connects technical depth with a vision for sustainable AI infrastructure!