Your ML Pipeline Meets the EU AI Act
On 7 June 2026, I gave my talk Your ML Pipeline Meets the EU AI Act in Grand Hall 1 at PyData London 2026. The talk resources are online: interactive slides, the companion notebook, an Evidently drift report, and the evidence-readiness checklist as PDF and Markdown.
I did not want to turn this into a standard conference recap. The more useful question is practical: What does the EU AI Act mean for an ordinary ML pipeline that still has to be trained, deployed, and monitored next week?

The Question That Sticks
I opened the talk with a small show-of-hands exercise: Who has a model in production that makes a decision about a person? A loan, a job application, an insurance quote, a fraud flag, something in that family. Then the follow-up: Who could still explain today why one specific decision six months ago came out the way it did?
This is where the room usually gets quieter. Not because the teams are doing bad work. More often, because our systems are excellent at serving requests and much worse at reconstructing decisions later.
The old operational question was: Do we have logs? Did the service respond, did it error, what was the latency? For high-risk systems, that is not enough. The harder question is: Can we reconstruct why? Article 12 of the EU AI Act is easy to read as a logging topic. In practice, it feels more like evidence architecture: not just recording what happened, but preserving enough context for someone else to understand it later.
Why Credit Scoring?
The talk follows a synthetic credit-risk-scoring example. It is not an exotic setup: collect data, build features, train a model, evaluate it, deploy it, monitor it. That is why I like it for this walkthrough. Many ML pipelines have the same shape, even when they are not deciding loans.
Credit scoring is also a place where the AI Act quickly becomes concrete. As of June 2026, the timeline is moving: After the political agreement on the AI Omnibus, rules for certain high-risk areas are set to apply from 2 December 2027, and product-integrated high-risk systems from 2 August 2028. The Council of the EU gives the same dates in its press release on the provisional agreement. I would not anchor too much on the exact deadline, though. The deadline may move; the gaps in the pipeline remain.
Evidence, Not Just Logs
I prefer starting with four plain questions before getting lost in articles and obligations:
- Lineage: What data shaped this decision?
- Tracking: Which model, parameters, metrics, and environment belong to this release?
- Explainability: Why did this specific result happen for this specific person?
- Monitoring: Is the system still behaving the way it was signed off?
Most teams have partial answers somewhere. A bit is in Git, a bit in MLflow, a bit in a ticket, a bit in a notebook, and a slightly worrying amount in people’s heads. That is usually the work: not buying a new tool first, but connecting the traces you already have so a future reviewer is not guessing.
Lineage Does Not End at the Dataset
A familiar uncomfortable moment: The model drifts in production, someone wants to compare it with the training state, and suddenly nobody is sure which data was actually used. Not roughly. Not “that table from back then”. Exactly.
DVC, LakeFS, Pachyderm, or MLflow Datasets are useful here because they make data states versionable. But that only gets you partway. dvc checkout reconstructs data; it does not reconstruct a decision. To reconstruct an actual decision, four things belong together:
- the data hash,
- the Git SHA of the code,
- the locked environment, such as
uv.lockorrequirements.txt, - the training and decision parameters.
The last part is easy to underestimate. Same data, same code, but a different scikit-learn version, and the decision boundary can move. The environment is not a footnote. It is part of the evidence.
Explanations Belong to the Run
Another less dramatic but equally dangerous case: Somewhere in the code there is a threshold of 0.4. Nobody on the current team remembers exactly why. The engineer who set it left two years ago. Still, that number helps decide every day who enters human review and who does not.
This is where MLflow is a handy anchor for me. A training run can be more than a place for metrics. It can keep the model, parameters, SHAP artifacts, model-card information, and lineage hints in one place. The explanation is no longer a loose screenshot in a notebook; it travels with the model.
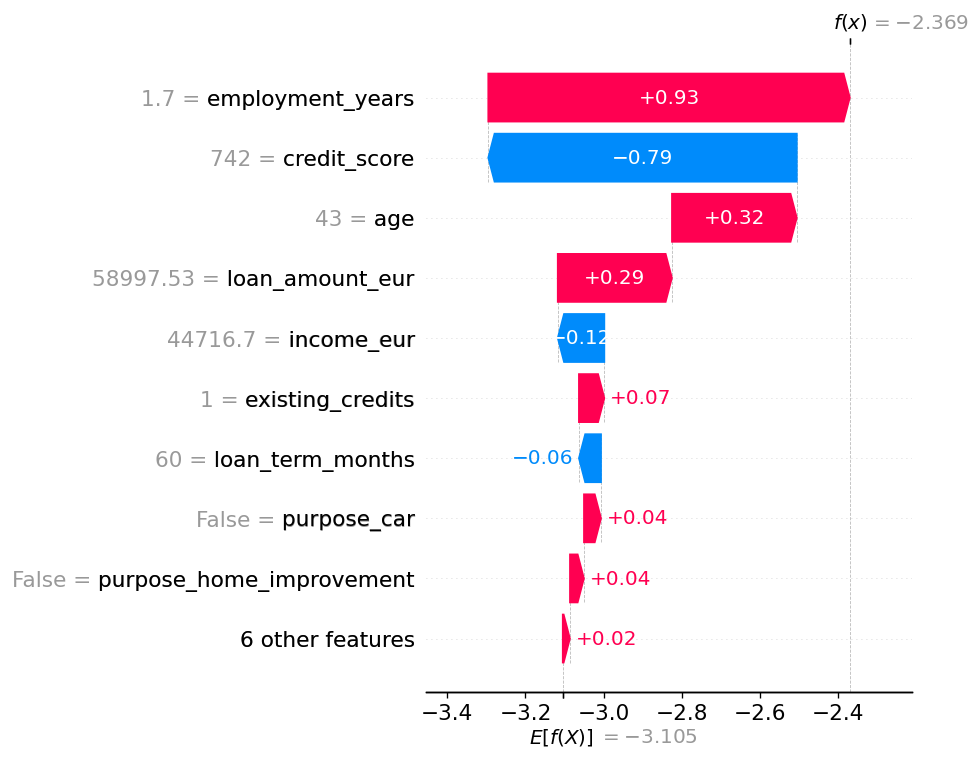
A SHAP plot is not compliance, of course. It is one piece of evidence. And even SHAP deserves care: Path-dependent and interventional SHAP answer different questions. For a regulated, appealable credit decision, I would defend interventional SHAP with a documented, versioned background dataset. More important than the exact choice is that the choice is deliberate and recorded.
The same applies to the threshold. “0.4 because it is in the code” should turn into something you can explain: calibration, cost matrix, fairness review, sign-off. Then the number is no longer magic. It is a decision with a paper trail.
Monitoring Is More Than Uptime
The third point is almost boring until it matters. The dashboard is green: Latency is fine, error rate is fine, uptime is fine. The model is “up”. But that says very little about whether it is still the model you signed off.
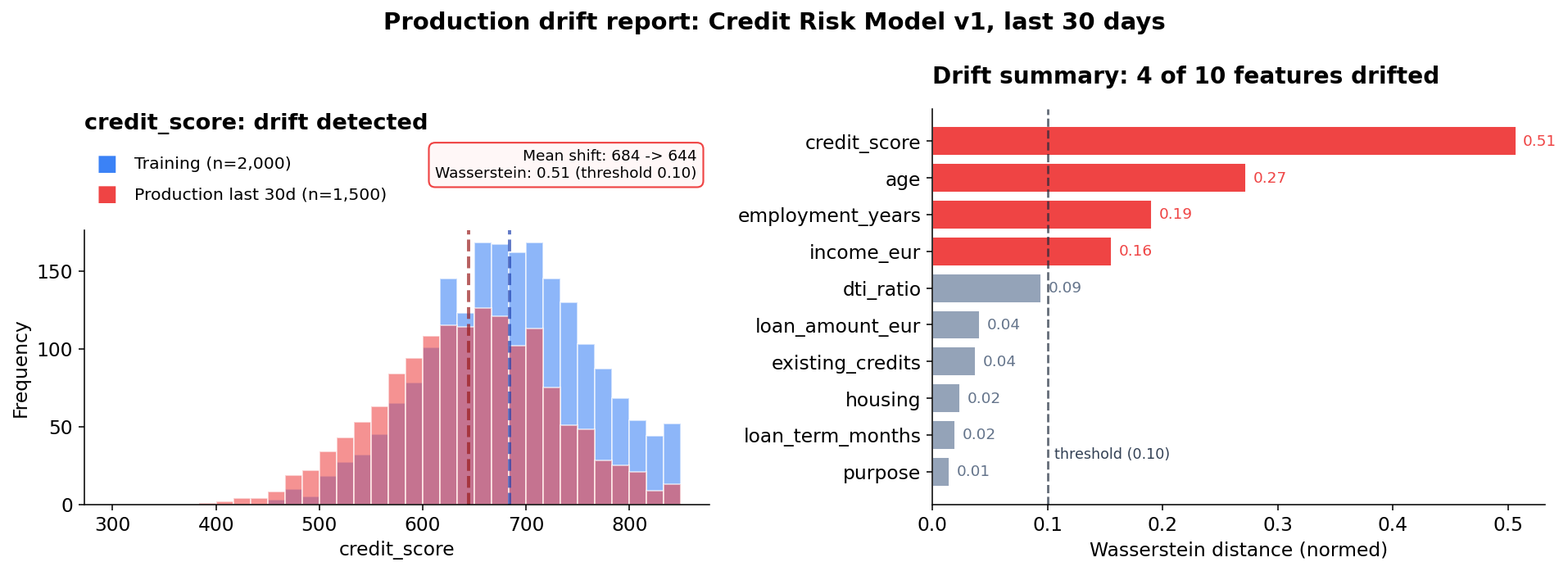
Evidently, NannyML, WhyLabs, or a custom Prometheus setup can make feature drift visible. The choice of tool is less important than the habit: Something has to watch decisions, not just infrastructure.
Feature drift is only the visible part. Outcome drift is where it gets practically and legally interesting. Are approval rates diverging between groups? Is the human override rate falling so low that human oversight has become rubber-stamping? A human who never disagrees is not oversight. They are part of the latency.
The Small Monday List
The evidence-readiness checklist from the talk is intentionally boring. It does not promise that a team can be “compliant” by Monday morning. It is there to help find the three most obvious gaps.
I would start bluntly: Is the risk classification documented? Can I reconstruct a training run with data, code, environment, and parameters? Are explanations stored as model artifacts? Do we have drift monitoring, fairness metrics, and a clear incident path?
That sounds less like grand regulation and more like good MLOps hygiene. Exactly. The AI Act does not invent many of these practices for high-risk systems; it makes them harder to treat as optional.
What Remains
The point I keep after the talk is simple: The EU AI Act does not force ML teams to reinvent their entire toolchain. It forces them to make the things they already claim provable.
Which data? Which code? Which model? Which explanation? Which release decision? Which production behaviour? Once those questions are answerable, regulation starts to feel less like something bolted onto engineering and more like a pretty good description of the system you would want anyway.
The old question was: Do we have logs? The better question remains: Can we reconstruct why?
All talk resources are here: slides, notebook, drift report, checklist, and tool links.