Deine ML-Pipeline trifft den EU AI Act
Am 7. Juni 2026 habe ich bei der PyData London 2026 in der Grand Hall 1 meinen Talk Your ML Pipeline Meets the EU AI Act gehalten. Die Ressourcen zum Talk sind online: interaktive Slides, Companion Notebook, ein Evidently-Drift-Report und die Evidence-Readiness-Checklist als PDF und Markdown.
Ich wollte daraus keinen klassischen Konferenzbericht machen. Interessanter ist die praktische Frage dahinter: Was heißt der EU AI Act eigentlich für eine ganz normale ML-Pipeline, die nächste Woche wieder trainiert, deployed und überwacht werden muss?

Die Frage, die hängen bleibt
Ich habe den Vortrag mit einer kleinen Handzeichenfrage begonnen: Wer hat ein Modell in Produktion, das über Menschen entscheidet? Kredit, Bewerbung, Versicherung, Fraud Flag, irgendetwas in dieser Richtung. Und dann: Wer könnte heute noch erklären, warum eine einzelne Entscheidung vor sechs Monaten genau so ausgefallen ist?
An der Stelle wird es im Raum meistens stiller. Nicht, weil die Teams schlechte Arbeit machen. Eher, weil unsere Systeme sehr gut darin sind, Requests zu bedienen, aber deutlich schlechter darin, später noch eine Entscheidung zu rekonstruieren.
Die alte Betriebsfrage war: Haben wir Logs? Hat der Service geantwortet, gab es Fehler, wie war die Latenz? Für hochriskante Systeme reicht das nicht mehr. Die härtere Frage lautet: Können wir später erklären, warum? Artikel 12 des EU AI Act wird schnell als Logging-Thema gelesen. In der Praxis fühlt es sich eher wie Evidence Architecture an: nicht nur festhalten, was passiert ist, sondern genug Zusammenhang aufheben, damit jemand anderes es nachvollziehen kann.
Warum Credit Scoring?
Im Talk läuft alles an einem synthetischen Credit-Risk-Scoring-Beispiel entlang. Das ist kein besonders exotischer Use Case: Daten sammeln, Features bauen, Modell trainieren, evaluieren, deployen, monitoren. Genau deshalb mag ich ihn für diese Diskussion. Viele ML-Pipelines sehen in ihrer Struktur ähnlich aus, auch wenn sie nicht über Kredite entscheiden.
Credit Scoring ist außerdem ein Bereich, in dem der AI Act schnell ernst wird. Stand Juni 2026 ist die Timeline zwar in Bewegung: Nach der politischen Einigung zum AI Omnibus sollen Regeln für bestimmte High-Risk-Bereiche ab 2. Dezember 2027 gelten, für produktintegrierte High-Risk-Systeme ab 2. August 2028. Der Rat der EU nennt dieselben Daten in seiner Pressemitteilung zur vorläufigen Einigung. Aber ich würde mich an der Frist nicht zu sehr festklammern. Die Deadline bewegt sich; die Lücken in der Pipeline bleiben.
Evidence statt nur Logs
Mir hilft es, den ML-Lifecycle zuerst in vier einfachen Fragen zu denken, bevor man sich in Artikeln und Pflichten verliert:
- Lineage: Welche Daten haben diese Entscheidung geprägt?
- Tracking: Welches Modell, welche Parameter, welche Metriken und welche Umgebung gehören zu diesem Release?
- Explainability: Warum kam dieses konkrete Ergebnis für diese konkrete Person heraus?
- Monitoring: Verhält sich das System in Produktion noch so, wie es freigegeben wurde?
Die meisten Teams haben irgendwo Antworten auf Teile davon. Ein bisschen liegt in Git, ein bisschen in MLflow, ein bisschen in einem Ticket, ein bisschen in einem Notebook und ein beunruhigender Rest in den Köpfen von Menschen. Dort steckt meistens die Arbeit: nicht zuerst neue Tools kaufen, sondern die vorhandenen Spuren so verbinden, dass später niemand raten muss.
Lineage endet nicht beim Datensatz
Ein unangenehmer Klassiker: Das Modell driftet in Produktion, jemand möchte mit dem Trainingsstand vergleichen, und plötzlich ist nicht mehr klar, welche Daten damals wirklich im Training waren. Nicht ungefähr. Nicht „die Tabelle von damals“. Sondern exakt.
DVC, LakeFS, Pachyderm oder MLflow Datasets sind dafür nützlich, weil sie Datenzustände versionierbar machen. Aber damit ist man nur ein Stück weiter. dvc checkout rekonstruiert Daten, aber noch keine Entscheidung. Für eine brauchbare Rekonstruktion gehören vier Dinge zusammen:
- der Datenhash,
- der Git-SHA des Codes,
- die gelockte Umgebung, zum Beispiel
uv.lockoderrequirements.txt, - die Trainings- und Entscheidungsparameter.
Der letzte Punkt wird oft unterschätzt. Gleiche Daten, gleicher Code, aber eine andere scikit-learn-Version, und schon kann die Entscheidungsgrenze anders aussehen. Das Environment ist nicht Beiwerk. Es ist Teil der Evidenz.
Erklärungen gehören zum Run
Noch so ein Fall, weniger dramatisch, aber genauso gefährlich: Im Code steht ein Threshold von 0.4. Niemand im aktuellen Team weiß mehr genau, warum. Der Kollege, der ihn gesetzt hat, ist seit zwei Jahren weg. Trotzdem entscheidet diese Zahl jeden Tag mit, wer in den Human Review kommt und wer nicht.
An dieser Stelle mag ich MLflow als einfachen Anker. Ein Trainingsrun kann mehr sein als ein Ort für Metriken. Er kann Modell, Parameter, SHAP-Artefakte, Model-Card-Informationen und Lineage-Hinweise an einer Stelle zusammenhalten. Dann liegt die Erklärung nicht als einzelner Screenshot in einem Notebook, sondern reist mit dem Modell mit.
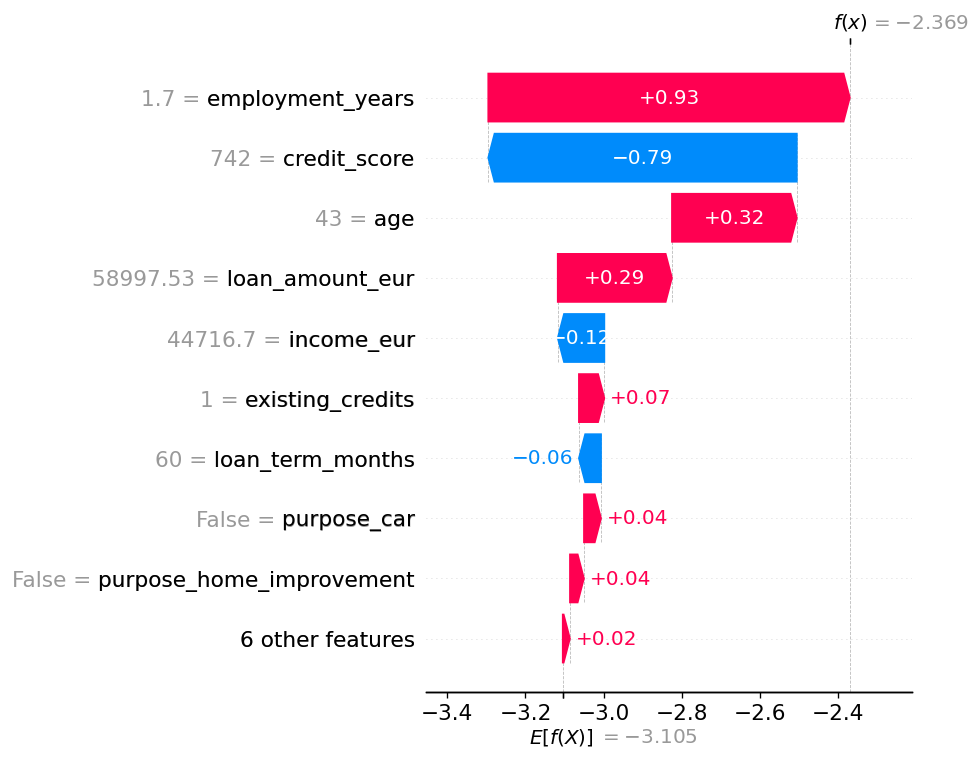
Natürlich ist ein SHAP-Plot keine Compliance. Er ist ein Stück Evidenz. Und selbst bei SHAP muss man genauer hinsehen: Path-dependent und interventional SHAP beantworten unterschiedliche Fragen. Für eine regulierte, anfechtbare Kreditentscheidung würde ich interventional SHAP mit dokumentiertem, versioniertem Background Dataset verteidigen. Wichtiger als die konkrete Wahl ist aber, dass sie überhaupt bewusst getroffen und festgehalten wird.
Ähnlich ist es beim Threshold. Aus „0.4, weil es im Code steht“ sollte etwas werden, das man erklären kann: Kalibrierung, Kostenmatrix, Fairness-Review, Sign-off. Dann ist die Zahl nicht mehr magisch, sondern ein nachvollziehbarer Entscheid.
Monitoring ist mehr als Uptime
Der dritte Punkt klingt fast langweilig, bis er weh tut. Das Dashboard ist grün: Latenz passt, Error Rate passt, Uptime passt. Das Modell ist also „up“. Nur sagt das sehr wenig darüber aus, ob es noch das Modell ist, das man freigegeben hat.
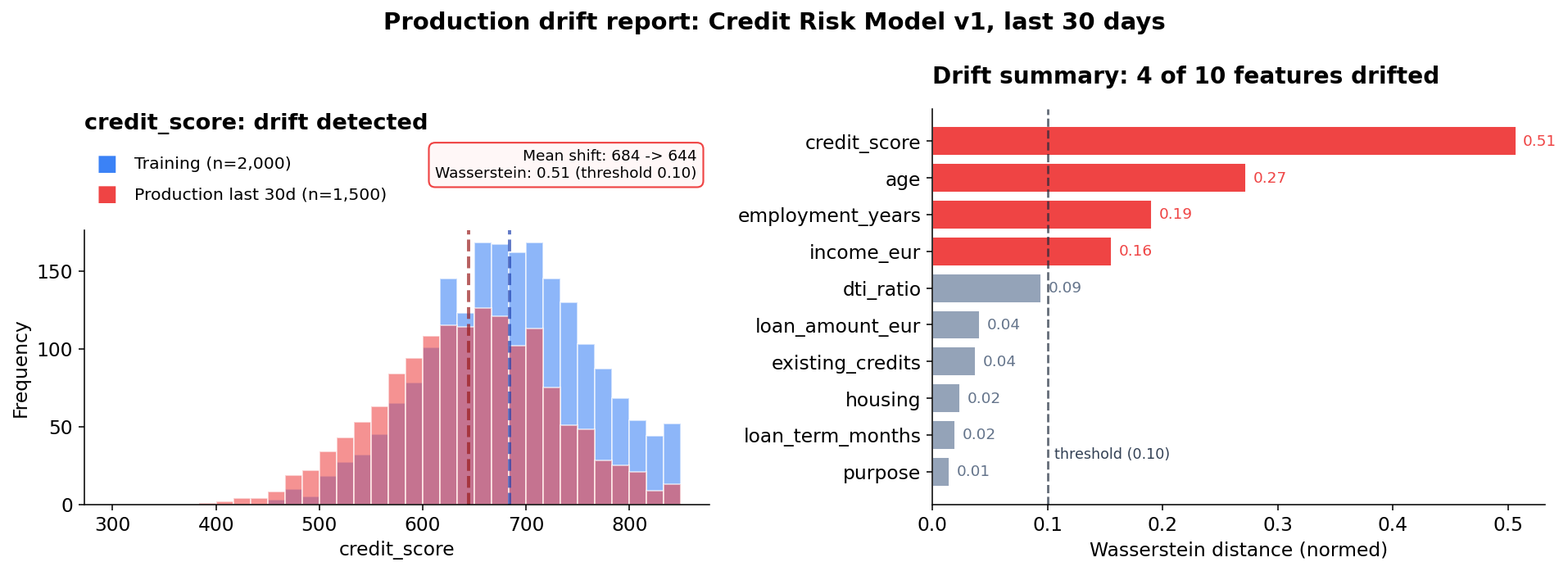
Evidently, NannyML, WhyLabs oder ein eigenes Prometheus-Setup können Feature Drift sichtbar machen. Die Toolfrage ist hier weniger wichtig als die Gewohnheit: Jemand muss die Entscheidungen beobachten, nicht nur die Infrastruktur.
Feature Drift ist dabei nur der gut sichtbare Teil. Spannender wird es bei Outcome Drift. Entfernen sich Approval Rates zwischen Gruppen? Sinkt die Override Rate der Menschen so weit, dass Human Oversight nur noch ein Abnicken ist? Ein Mensch, der nie widerspricht, ist keine Aufsicht. Er ist Teil der Latenz.
Die kleine Montag-Liste
Die Evidence-Readiness-Checklist aus dem Talk ist absichtlich bodenständig. Sie verspricht nicht, dass ein Team am Montagmorgen „compliant“ ist. Sie soll helfen, die drei offensichtlichsten Lücken zu finden.
Ich würde ganz schlicht anfangen: Ist die Risk Classification dokumentiert? Kann ich einen Trainingsrun inklusive Daten, Code, Environment und Parametern rekonstruieren? Liegen Erklärungen als Artefakte beim Modell? Gibt es Drift Monitoring, Fairness-Metriken und einen klaren Incident Path?
Das klingt weniger nach großer Regulierung als nach guter MLOps-Hygiene. Genau das ist der Punkt. Der AI Act macht viele dieser Praktiken für High-Risk-Systeme nicht neu, sondern verbindlicher.
Was bleibt
Was ich aus dem Talk mitnehme, ist schlicht: Der EU AI Act zwingt ML-Teams nicht dazu, ihre komplette Toolchain neu zu erfinden. Er zwingt sie dazu, die Dinge, die sie ohnehin behaupten, beweisbar zu machen.
Welche Daten? Welcher Code? Welches Modell? Welche Erklärung? Welche Freigabe? Welches Produktionsverhalten? Wenn diese Fragen beantwortbar sind, fühlt sich Regulierung plötzlich weniger wie etwas Aufgesetztes an und mehr wie eine ziemlich gute Beschreibung eines Systems, das man sowieso haben möchte.
Die alte Frage war: Haben wir Logs? Die bessere Frage bleibt: Können wir rekonstruieren, warum?
Alle Ressourcen zum Talk liegen hier: Slides, Notebook, Drift Report, Checklist und Tool-Links.